
Complete guide to combine object detection with vision language models for accurate text extraction

Written by Henry Navarro
Introduction 🎯
Two powerful frameworks that we’ve explored separately in previous articles: Ultralytics YOLO 11, a highly accurate object detection model, and Ollama, a framework for deploying LLM models. But what happens when we combine them to create a highly precise OCR system? That’s exactly what I’m going to show you today.
This isn’t just about license plate recognition – although that’s our primary example. The architecture and methodology I’m presenting can be applied to extract text from various sources: document sections, signs, labels, or any scenario where you need to first detect regions of interest and then extract text from them with high accuracy.
The key insight here is using two-stage processing: first, we use a pre-trained Ultralytics YOLO 11 model to detect and locate text regions (like license plates), then we crop those regions and pass them to Ollama’s vision language models for accurate text extraction. This approach ensures we’re only reading text from areas we’re specifically interested in, dramatically improving accuracy and reducing false positives.
Setting Up the Development Environment 🛠️
Before we dive into the OCR implementation, let’s set up our development environment and clone the repository that contains all the necessary code for this tutorial.
Step 1: Create a Virtual Environment When working with Python projects, it’s always recommended to work in virtual environments. This keeps your dependencies organized and prevents conflicts between different projects. You will find a good tutorial about hout to set up right here.
# Create a virtual environment
mkvirtualenv ultralytics-ocrStep 2: Clone the Repository and install dependencies I’ve created a complete repository with all the code needed for this tutorial. It belongs to my company NeuralNet, where we provide AI consulting services for businesses.
git clone https://github.com/NeuralNet-Hub/ultralytics-ollama-OCR.git
cd ultralytics-ollama-ocr
pip install -r requirements.txtThis installation might take a few minutes as it downloads all the required libraries including Ultralytics, Gradio, and other dependencies.
Step 4: Launch the Application Once everything is installed, you can launch the Gradio interface:
python main.py --model alpr-yolo11s-aug.ptThis will take a few seconds to start, and then you can navigate to http://localhost:7860 to see the interface.
Understanding the Interface Components 📊
Once the application is running, you’ll see a Gradio interface with several key components:
Image Upload Section:
- Image Input: Where you can upload images or select from the provided demo images
- Demo Images: Pre-loaded example images from RoboFlow (a platform for labeling data) that you can use for testing
Model Configuration:
- Confidence Threshold: A crucial parameter for Ultralytics YOLO 11 models in Computer Vision – this determines how confident the model needs to be before detecting an object
- Intersection Over Union (IOU): An important metric for object detection that helps eliminate duplicate detections (I recommend researching this if you’re new to Computer Vision)
Ollama Server Configuration:
- Ollama Server URL: Where your Ollama server is deployed
- Vision Model Selection: Choose from available vision language models
If you don’t know how to install and deploy Ollama, I have comprehensive guides comparing it with other frameworks that you can find in our blog neuralnet.solutions/blog.
Choosing the Right Vision Model 👁️
What are Vision Models?
Vision models are like traditional LLMs, but with a crucial difference: besides being able to answer questions like “give me Python code that does A, B, and C,” you can also pass them an image and ask “describe this image” or “read the text in this image.”
Recommended Models:
For this tutorial, I’ll be using Qwen 2.5 VL (Vision Language) – one of my favorite models that we’ve tested extensively in previous articles.
Note: At the time of creating this tutorial, Qwen 3 Vision Language hasn’t been released yet, so we’ll use version 2.5, which is still excellent for our purposes.
Available Vision Models:
You can find all available vision models at ollama.com/models. Look for models with the “vision” tag – any of these could work for our OCR system:
- Qwen 2.5 VL
- LLaVA models
- MiniCPM-V
- And many others
Understanding the Two-Stage OCR Architecture 🏗️
Traditional OCR systems read all text in an image indiscriminately. If you have a car with a license plate plus other text, standard OCR extracts everything – creating noise and reducing accuracy.
Our solution uses intelligent two-stage processing:

How It Works:
- Ultralytics YOLO 11 Detection: Custom-trained model identifies and locates license plates
- Image Cropping: Extract only the detected regions
- Ollama Processing: Vision language model reads text using natural language prompts like “read this license plate and return it in JSON format”
- Result Integration: Combine coordinates with extracted text data
Model Training Transparency:
All training data, metrics, and experimental results are publicly available on my Weights & Biases project. You can explore detailed metrics including recall, precision, mAP scores, GPU power consumption, and complete training curves for all three model variants I’ve developed.
Why This Approach Works:
By pre-selecting regions of interest, we guarantee that text extraction only happens on areas we actually care about. No more reading unwanted background text, signs, or vehicle logos.
This architecture represents the best of both worlds: the speed and precision of computer vision object detection combined with the intelligence and flexibility of modern vision language models.
Testing the System 🧪
Let’s put our OCR system to work with a practical test using the demo images provided in the interface.
Quick Test Process:
- Select a Demo Image: Choose one image from your computer.
- Configure Settings: Set confidence threshold (try 0.3-0.5) and adjust IOU as needed.
- Ensure Ollama Connection: Verify your Ollama server is running with a vision model like Qwen 2.5 VL.
- Process Image: Click the process button and watch the magic happen.

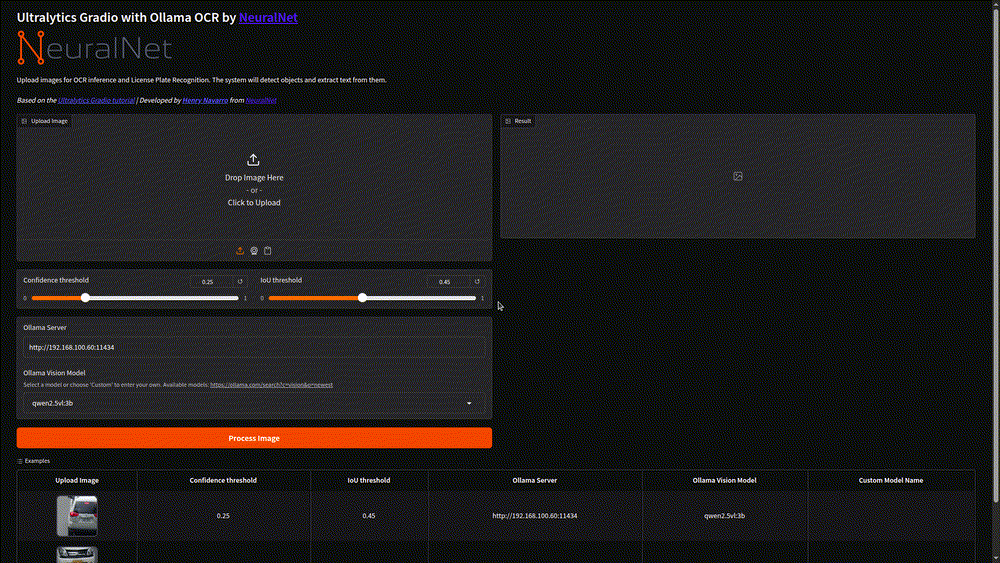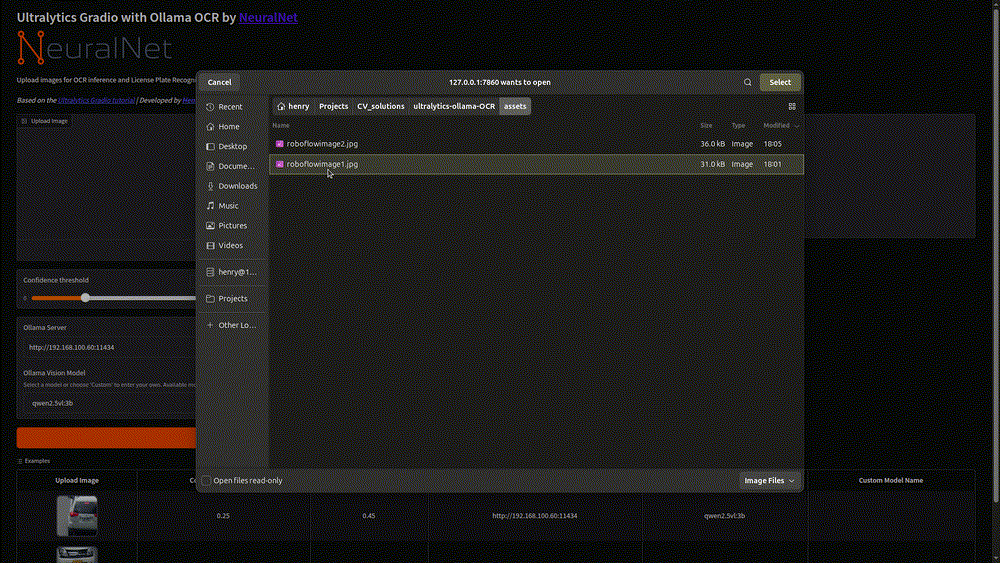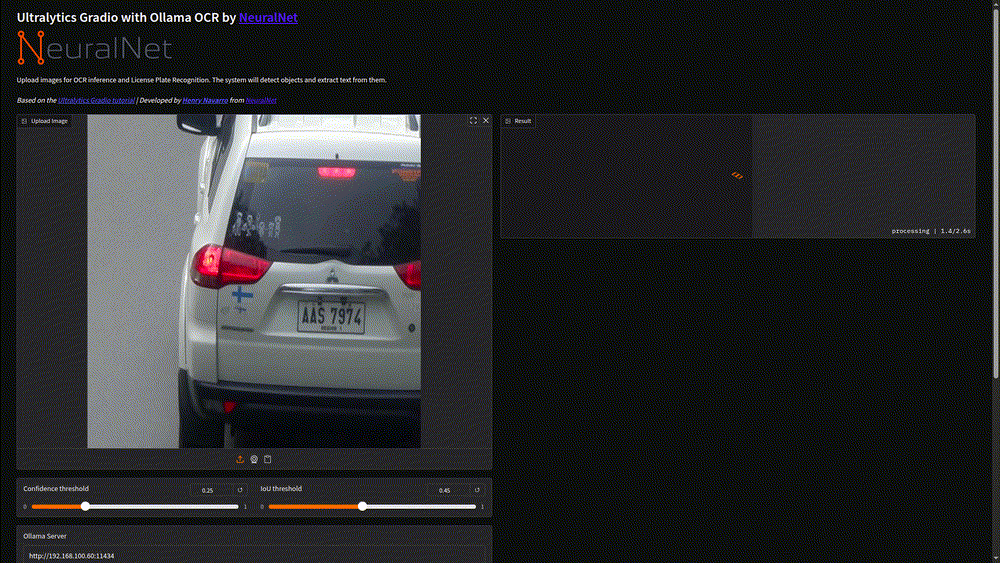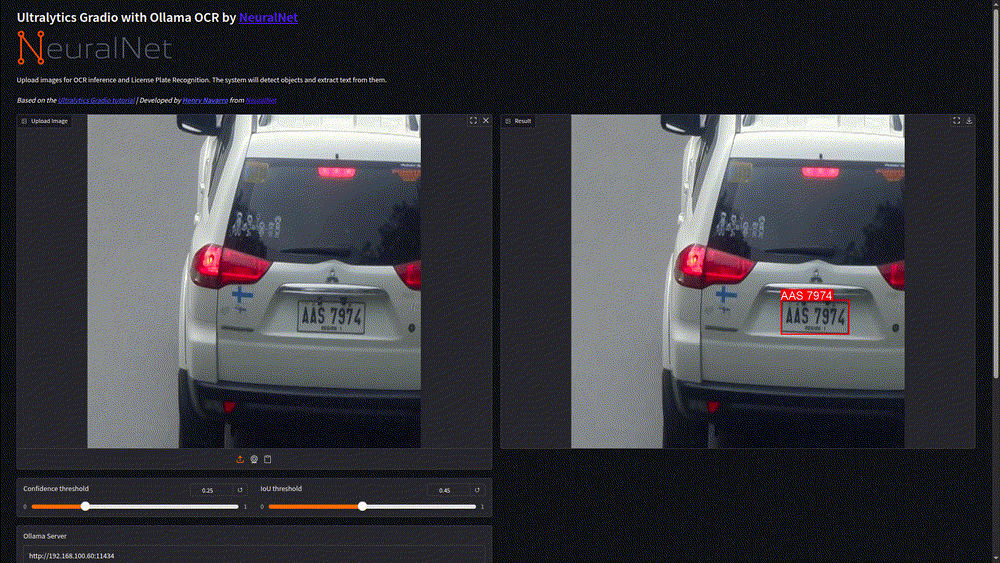
What You’ll See:
- Detection Boxes: Ultralytics YOLO 11 draws bounding boxes around detected license plates
- Extracted Text: Clean, accurate text reading from each detected region
- JSON Output: Structured data format perfect for integration with other systems
- Confidence Scores: Reliability metrics for both detection and text extraction
The system processes images in seconds, demonstrating the efficiency of our two-stage architecture. You can experiment with different confidence thresholds to see how it affects detection sensitivity.
📊 Weights & Biases Dashboard — Live Training Metrics
Need Professional Computer Vision Solutions for Your Business? 🏢
While this tutorial shows you how to build OCR systems with Ultralytics YOLO 11 and Ollama, many enterprises need more sophisticated computer vision solutions tailored to their specific use cases. That’s exactly what we specialize in at NeuralNet Solutions.
Why Choose Professional Computer Vision Development?
The OCR system we’ve built today works great for learning and small-scale applications, but enterprise computer vision requires additional capabilities:
- Custom Model Training: Models trained on your specific data and use cases
- Production Scalability: Handle thousands of images per second with optimized pipelines
- Multi-Modal Integration: Combine object detection, OCR, classification, and tracking
- Edge Deployment: Optimize models for mobile devices, embedded systems, and edge computing
- Real-Time Processing: Live video stream analysis with minimal latency
Enterprise Computer Vision Solutions 🎯
Our team transforms proof-of-concept computer vision projects into production-ready systems:
✅ Custom Ultralytics YOLO 11 Training: Object detection models trained on your specific objects and environments
✅ Advanced OCR Pipelines: Multi-language text extraction with preprocessing and post-processing
✅ Video Analytics: Real-time object tracking, behavior analysis, and anomaly detection
✅ Quality Control Systems: Automated inspection and defect detection for manufacturing
✅ Document Intelligence: Advanced form processing, table extraction, and document classification
✅ Edge Optimization: Deploy models on NVIDIA Jetson, mobile devices, and embedded systems
Get Started with a Free Computer Vision Consultation 📞
Have a specific computer vision challenge? Let’s discuss how we can solve it with custom AI solutions designed for your needs.
What you get in our 30-minute consultation:
- Analysis of your computer vision requirements and challenges
- Live demo of similar solutions we’ve built for other clients
- Technical architecture recommendations for your specific use case
📅 Book Your Free Consultation – No sales pressure, just expert advice on whether computer vision can transform your business operations.
Questions? Let’s Talk:
- 🌐 Website: neuralnet.solutions
- 💼 LinkedIn: Connect with Henry
- ✉️ Email: Available through our website contact form
Don’t let manual processes slow down your business. The companies implementing intelligent computer vision today will lead their industries tomorrow.